前一天的示範中,已經為大家介紹如何分析每個月的會員註冊人數,老闆在看完會員人數後,好奇地問了一句,這些會員中會購買商品的轉換率是多少? 所以啦,負責資料分析的你便開始動工,結合訂單資料來查找囉!
orders = read.csv("input/orders.csv", stringsAsFactors=FALSE, fileEncoding="big5")
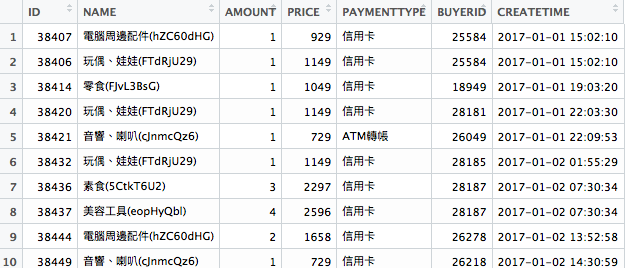
看到訂單資料中有個column 是BUYERID 了吧,我們將這個BUYERID 萃取出來。
buyer_list <- orders %>%
distinct(BUYERID)
buyer_list <- buyer_list$BUYERID
dplyr套件中 distinct函式是個可以去除重覆並找出唯一值的方法,我們指定BUYERID ,因此我們得到一個存有消費紀錄的會員ID vector。
result <- user %>%
mutate(Month = as.Date(user$CREATETIME, "%m/%d/%Y %H:%M:%S")) %>%
mutate(Month = substring(Month,1,7)) %>%
mutate(HasBought = ID %in% buyer_list)
接著,我們在dplyr中多加一個mutate ,使用%in% 字符,他的會回傳TRUE/FALSE,來決定該值是否存在於其中
最後再用一次group_by() 就可以得到我們要的結果啦! 而group_by的參考值以Month 和HasBought 兩者來區分。
result <- user %>%
mutate(Month = as.Date(user$CREATETIME, "%m/%d/%Y %H:%M:%S")) %>%
mutate(Month = substring(Month,1,7)) %>%
mutate(HasBought = ID %in% buyer_list) %>%
group_by(Month, HasBought) %>%
summarise(MembersCount = n())
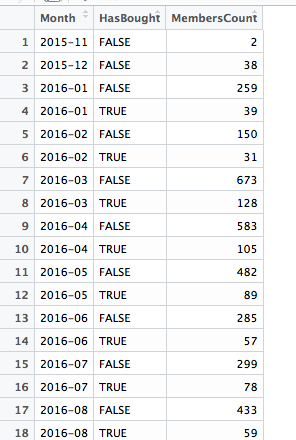
最後再用ggplot 畫出圖表。
ggplot(result, aes(x=Month, y=MembersCount, fill=HasBought)) +
geom_bar(stat="identity")
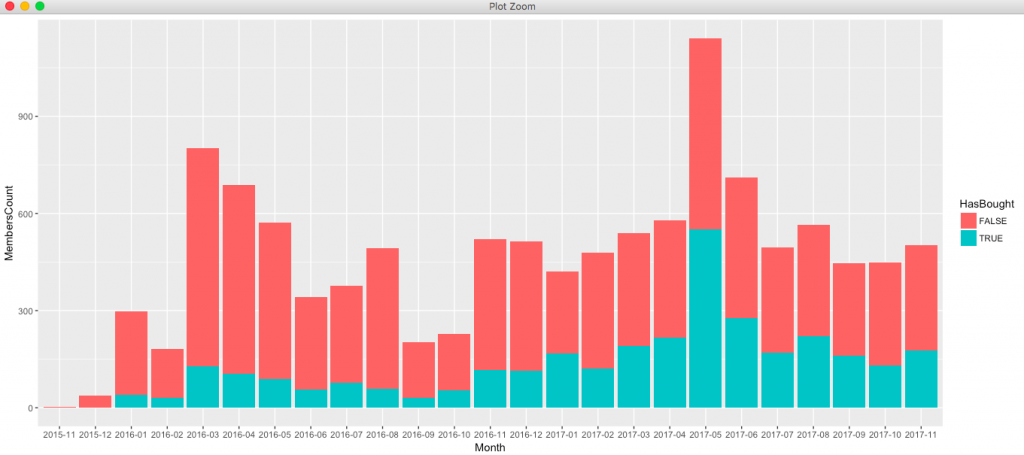
由此發現,其實註冊會員後但有購買紀錄其實不多啊...(資料是亂數產生)
ref:
day3原始碼
您好:想請教您 當你將orders的BUYERID抽出,並使用distinct去除重覆並找出唯一值
但為甚麼還要加buyer_list <- buyer_list$BUYERID,我有試不加這句
統計圖跑出來全部是FALSE,不知這句的用意為何?請不吝告知!
哈 文章有點久了也有好一陣子沒有用R了
憑直覺回答你
在
buyer_list <- orders %>%
distinct(BUYERID)
這邊,buyer_list還是一整個資料表 (就是所有column都有)
但我們之後用來做group的是只要根據BUYERID這一個column
所以才會有一行
buyer_list <- buyer_list$BUYERID
不然拿整個資料表去做ID %in% buyer_list
一定都是False
因為兩個資料型態完全不一樣
了解了!謝謝您
您的文章給我很多的啟發
並且很實務


